library(tidyverse)
theme_set(theme_classic())
source("https://github.com/jjcurtin/lab_support/blob/main/format_path.R?raw=true")
path_models <-"~/mnt/standard/risk/models/ema" # format_path("studydata/risk/models/ema", "restricted")
preds_hour<- read_rds(file.path(path_models,
"outer_preds_1hour_0_v5_nested_main.rds"))
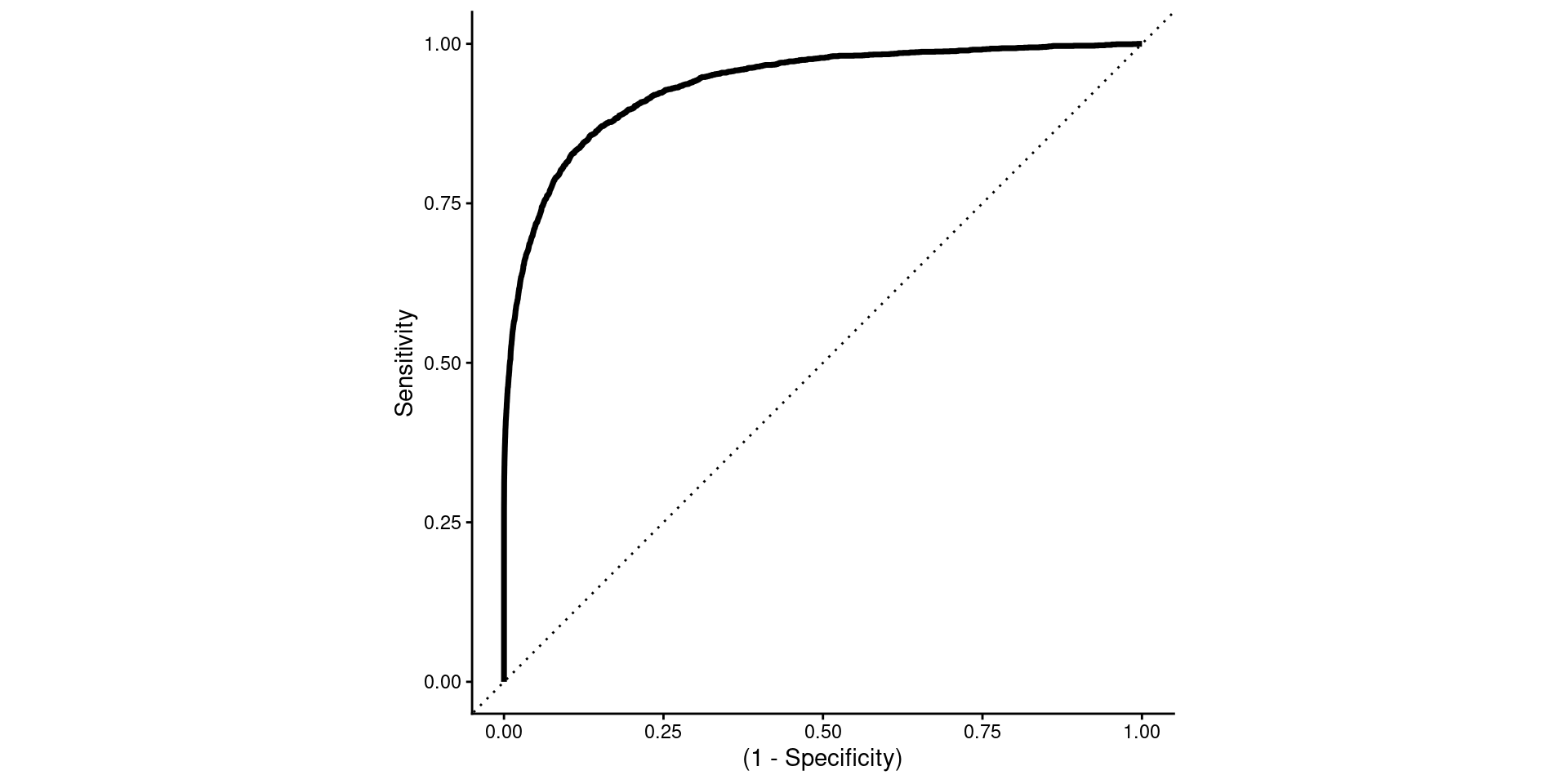
roc_hour <- preds_hour|>
yardstick::roc_curve(prob_beta, truth = label)Option 1 - Sensitivity vs. 1 - Specificity
- More common terms
- 1 - Specificity is confusing!
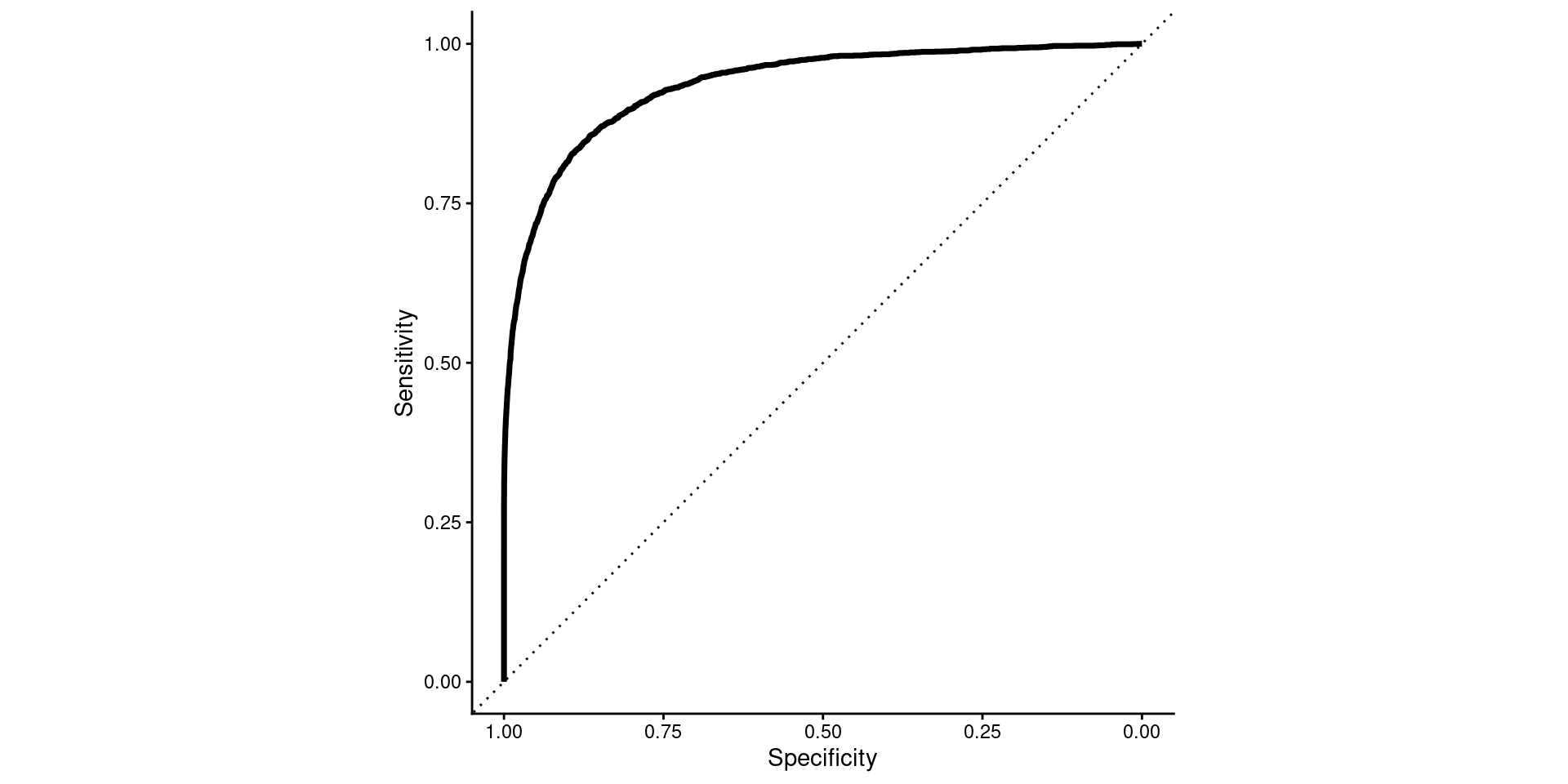
Option 2
- More common terms
- Sensible (though reversed) axis
- My preferred format
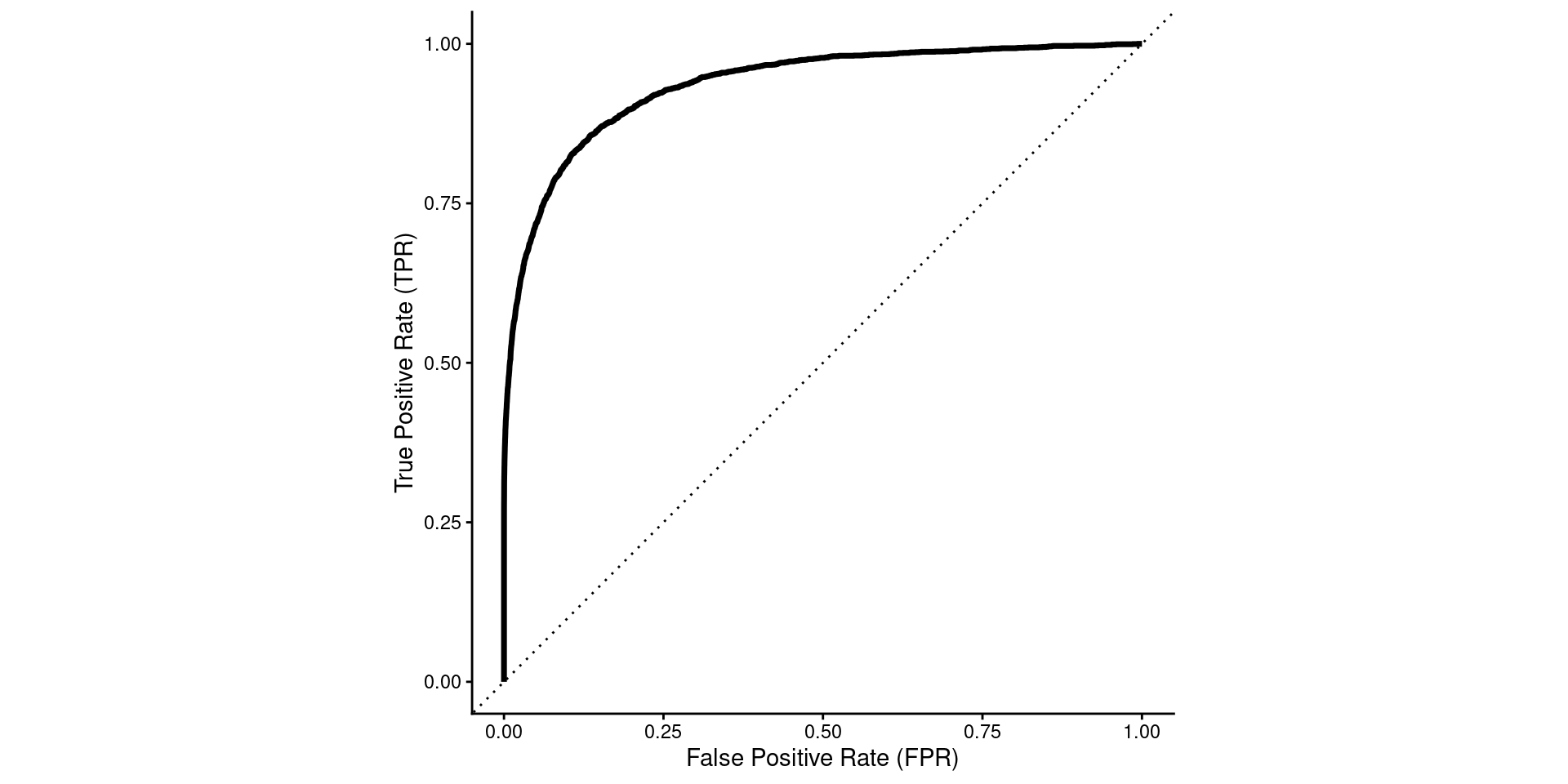
Option 3 - TPR vs. FPR
- sensible axes
- Less common terms
- But coming to prefer (depending on audience)
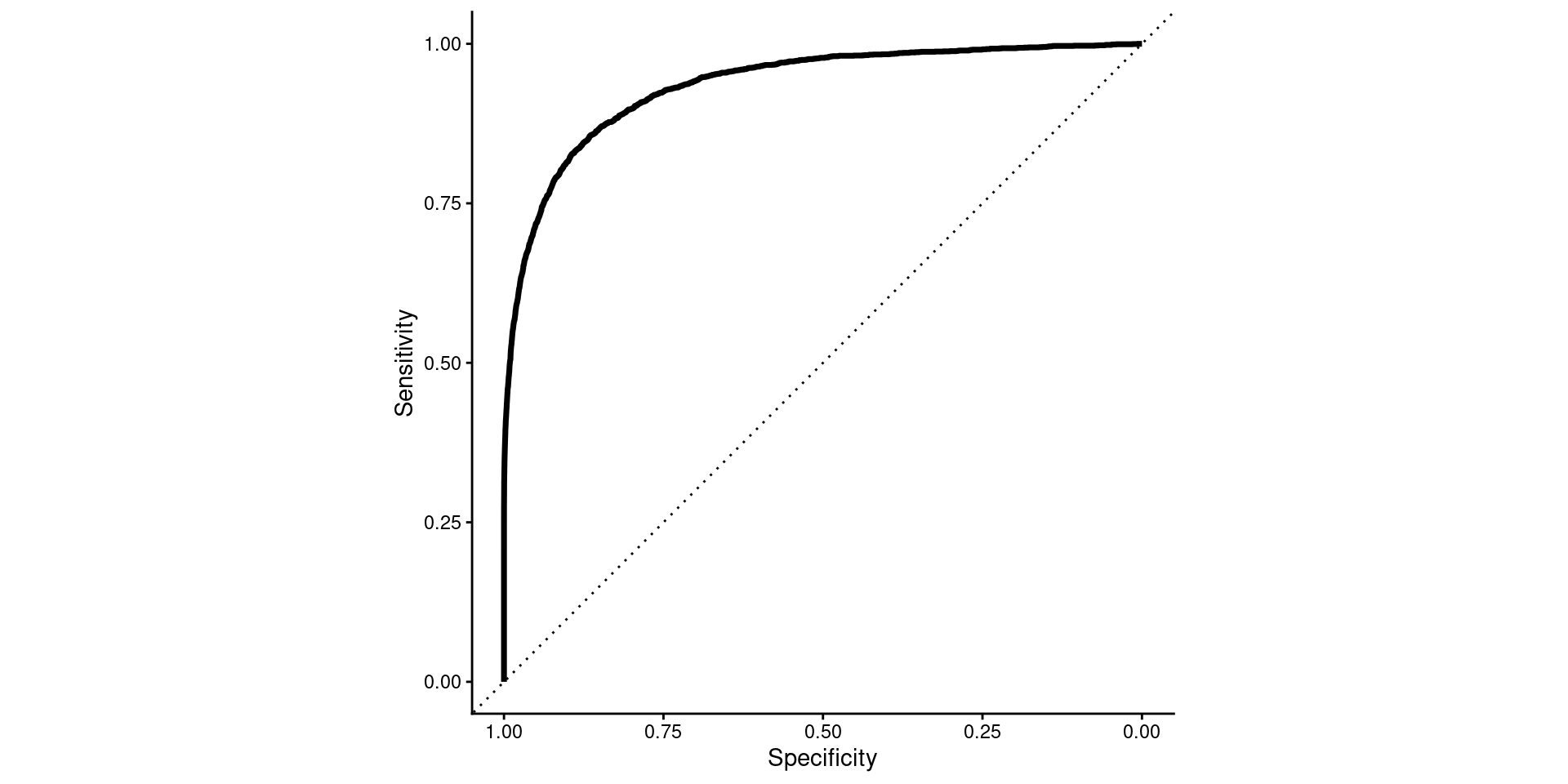
- Why is top right perfect performance
- Thresholds
- Interpretation of auROC and the diagonal line
- Can we go over some more concrete (real-world) examples of when it would be a good idea to use a different threshold for classification?
- Are there any techniques to optimize decision thresholds? Or is it trial and error.
- How does AUROC perform in highly imbalanced datasets
- Sensitivity vs. Specificity Trade-offs, is it always true increase in one will sacrifice the other
Kappa
- expected accuracy
- given majority class proportion
- by chance given base rates
- ratio of improvement above expected accuracy
