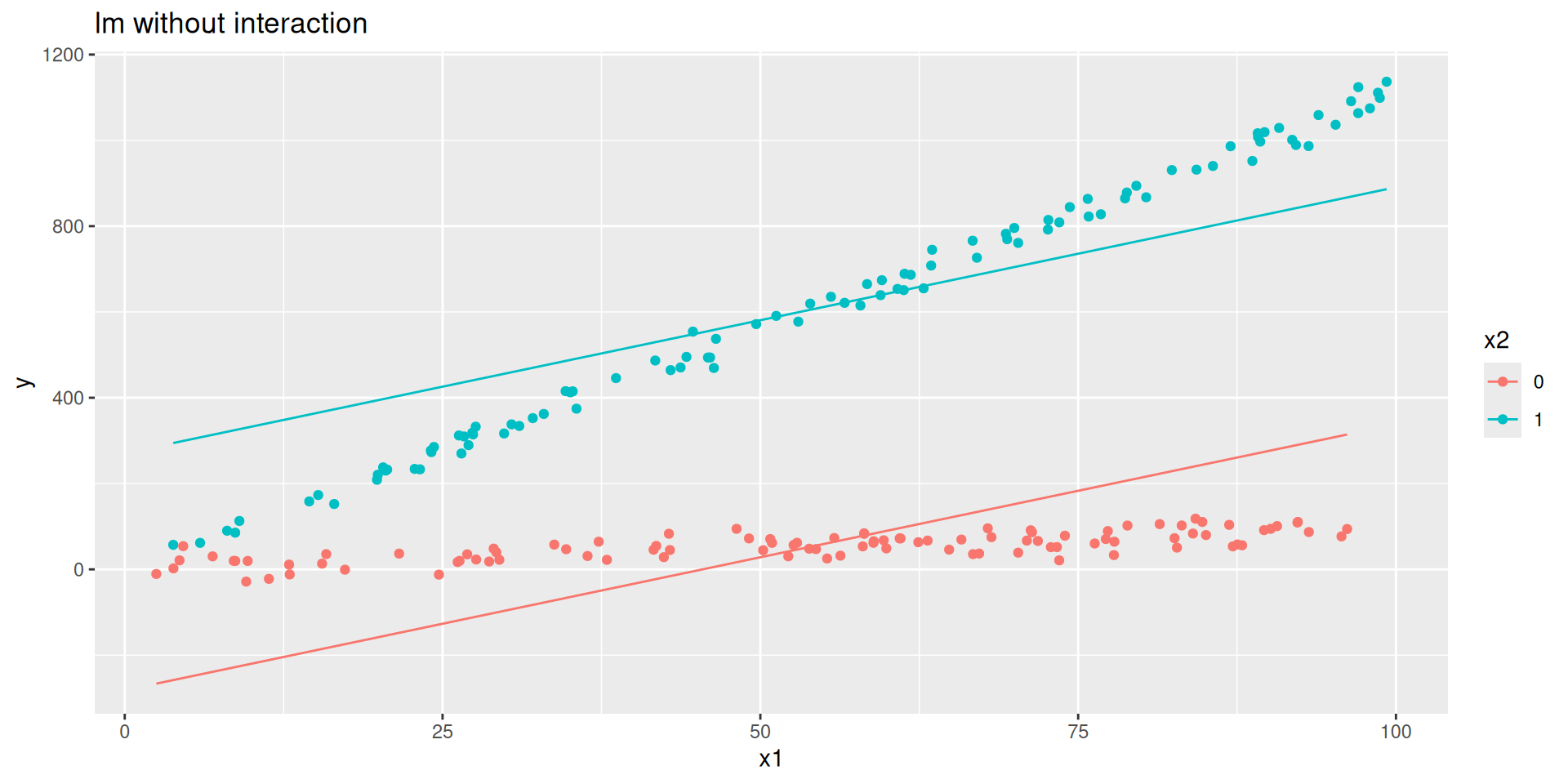
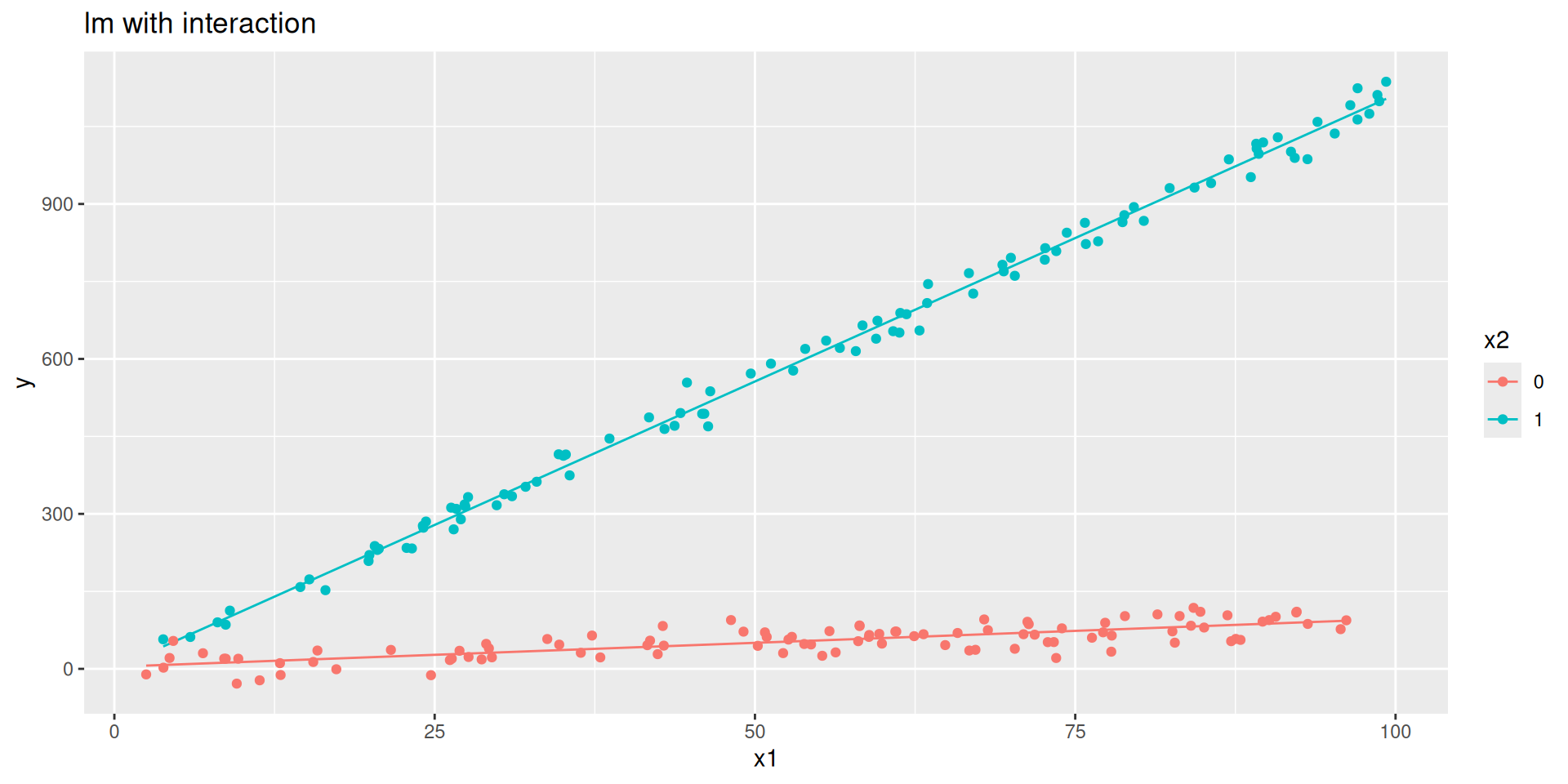
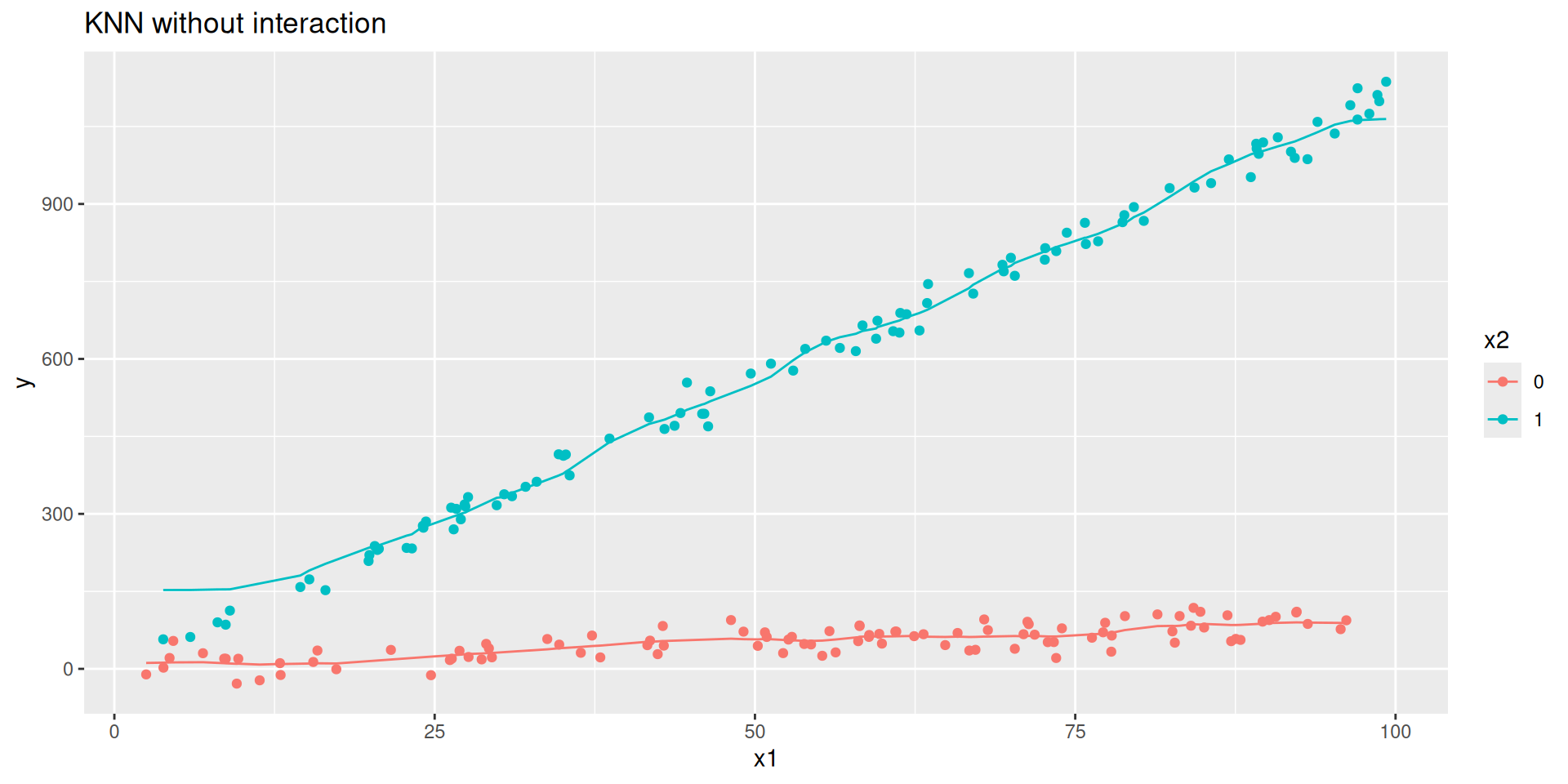
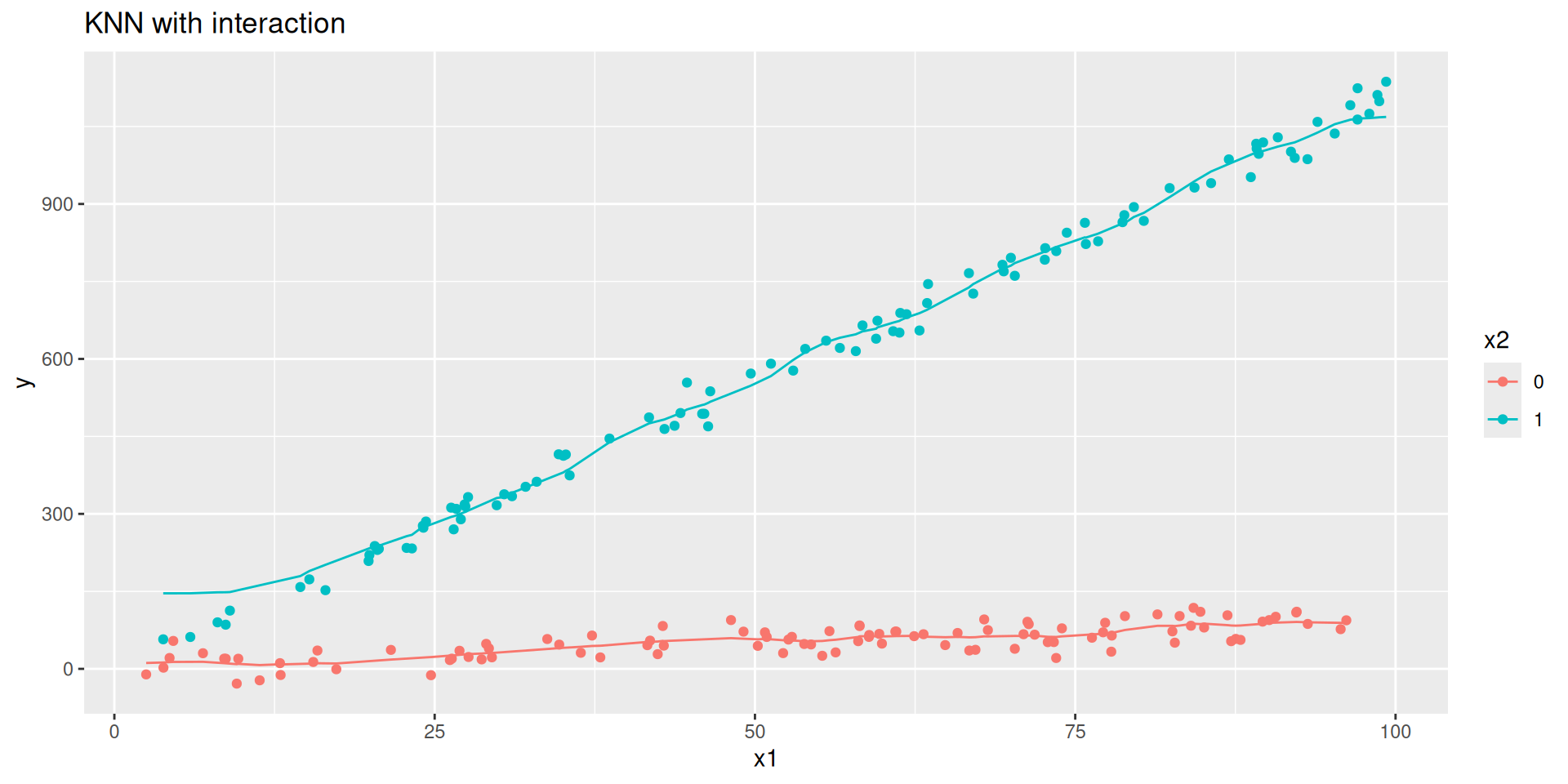
Code
library(tidymodels)
n <- 200
set.seed(5433)
d <- tibble(x1 = runif(n, 0,100), # uniform
x2 = rep(c(0,1), n/2), # dichotomous
x1_x2 = x1*x2, # interaction
y = rnorm(n, 0 + 1*x1 + 10*x2 + 10* x1_x2, 20)) #DGP + noise
fit_lm <-
linear_reg() |>
set_engine("lm") |>
fit(y ~ x1 + x2, data = d)
fit_lm_int <-
linear_reg() |>
set_engine("lm") |>
fit(y ~ x1 + x2 + x1_x2, data = d)
fit_knn <-
nearest_neighbor(neighbors = 20) |>
set_engine("kknn") |>
set_mode("regression") |>
fit(y ~ x1 + x2, data = d)
fit_knn_int <-
nearest_neighbor(neighbors = 20) |>
set_engine("kknn") |>
set_mode("regression") |>
fit(y ~ x1 + x2 + x1_x2, data = d)
d <- d |>
mutate(pred_lm = predict(fit_lm, d)$.pred,
pred_lm_int = predict(fit_lm_int, d)$.pred,
pred_knn = predict(fit_knn, d)$.pred,
pred_knn_int = predict(fit_knn_int, d)$.pred)